Mask RCNN implementation
参考资料
要充分理解maskRCNN建议先通读RCN的系列论文了解主题脉络, 然后参考代码实现了解细节。
本文内容基于matterport的实现版本,这里有一份官方博客介绍了一些实现细节,推荐阅读。
说明
由于相关资料网络上不少,本文仅描述一些其他资料很少提及或者说明的部分。
整体架购
下图为mask-rcnn的整体实现框架
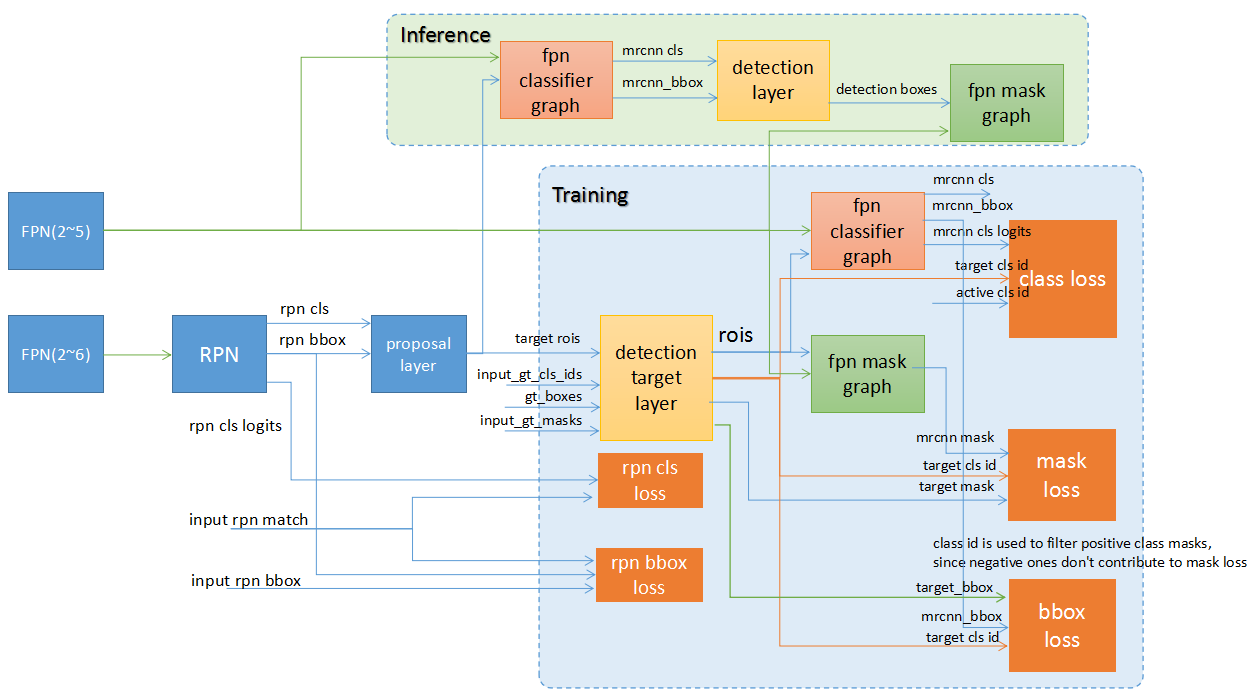
训练和推导过程的区别
从图中可以看出来,MASK-RCNN的训练和推导过程略有不同。 1) 训练的时候,分类器使用的region proposal是根据ground truth和rpn的结果计算出来的,而推导的时候,直接使用RPN的结果。 2) 训练的时候分类器和mask生成器是并行的,推导的时候是串行的,先进行分类和bbox的回归,然后使用其结果进行mask的生成。 3)注意虽然流程不同,但是不一样的部分(detection target layer和detection layer)是固定的流程,没有参数和‘可学习’的部分。其他主要的需要训练学习的网络是一样的。
多任务训练
Backbone一般直接使用训练好的模型,比如ResNet,VGGNet等。RPN网络、类别判定和BBox回归网络,Mask生成网络,各自都有对应的loss,几个模块可以同时学习,而且据说同时训练效果更好。
FPN和RPN的对应关系
具体来说,FPN的各层feature都应用到同一个RPN, 但是对应不同的anchor box的大小。这里和anchor box大小的对应关系是隐含的。比如对于512512的输入图片,如果feature是128128的,那么对应的anchor box是8*8。不过这个对应关系是可配置的(RPN_ANCHOR_SCALES, BACKBONE_STRIDES),也可以有不一样的对应关系,如果修改的需要注意reception field,以及在构造ground truth bbox的时候要对应好。
FPN在分类/BBOX回归/mask生成是如何使用
根据RPN生成的BBOX的大小,对应到不同的feature层。matterport的代码这里是写死的。对于224*224的ROI,对应到FPN的P4. 此处有个疑问,对于不同的输入图片大小,是不是应该有不同的对应关系。
FPN的各层feature其实没有合起来一起用,RPN用不同层的feature对应不同的anchor box的大小,类别判定和bbox回归,以及mask生成都是选定某一层feature作为网络的输入。
FPN
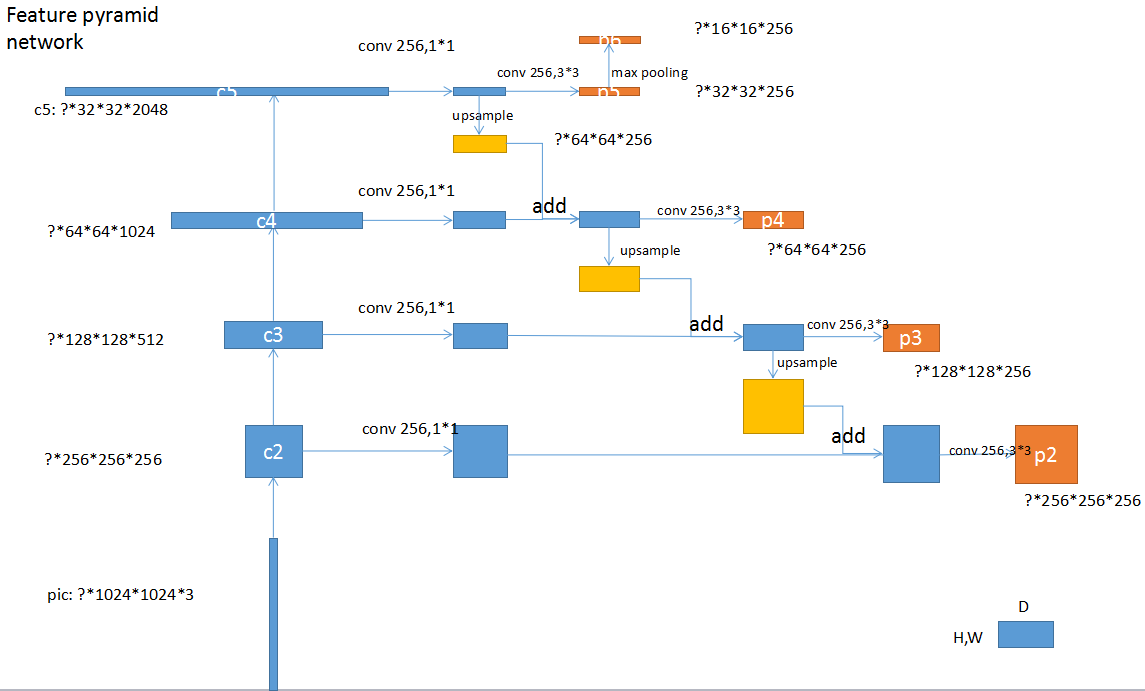 FPN上层upsample之后和下层直接相加,channel数不变。这里和Unet不一样,Unet用连接(concatenation)的方式合并上下层feature,得到的channel数会变多。
FPN上层upsample之后和下层直接相加,channel数不变。这里和Unet不一样,Unet用连接(concatenation)的方式合并上下层feature,得到的channel数会变多。
RPN
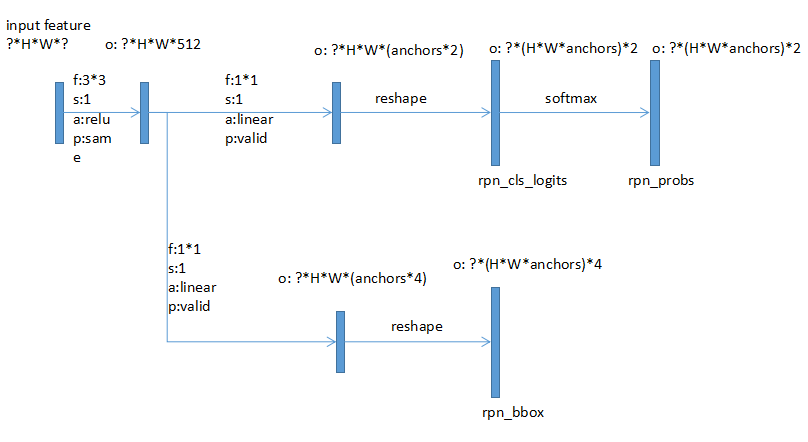
论文中RPN是在featurelayer上使用33的区域作为输入,在实现的时候就是简单的33卷积,每个位置都生成结果。
RPN与Proposal Layer的对应关系
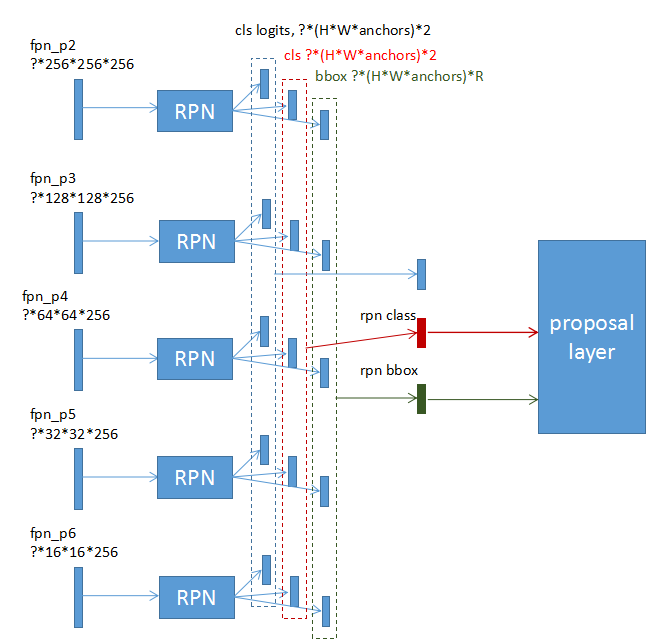 FPN的不同feature层都输入到rpn网络,生成一组RPN结果,然后将这些结果合并起来,输入到ProposalLayer。需要注意对应关系,因为某个RPN的结果对应哪个Box Scale,哪个Box ratio,以及对应原始图片哪个Position,都是固定的,后续计算Loss的时候需要和Ground Truth对应起来。在ProposalLayer之后这个对应关系就不需要了,因为Bbox本身记录了位置。
FPN的不同feature层都输入到rpn网络,生成一组RPN结果,然后将这些结果合并起来,输入到ProposalLayer。需要注意对应关系,因为某个RPN的结果对应哪个Box Scale,哪个Box ratio,以及对应原始图片哪个Position,都是固定的,后续计算Loss的时候需要和Ground Truth对应起来。在ProposalLayer之后这个对应关系就不需要了,因为Bbox本身记录了位置。
分类和bbox回归
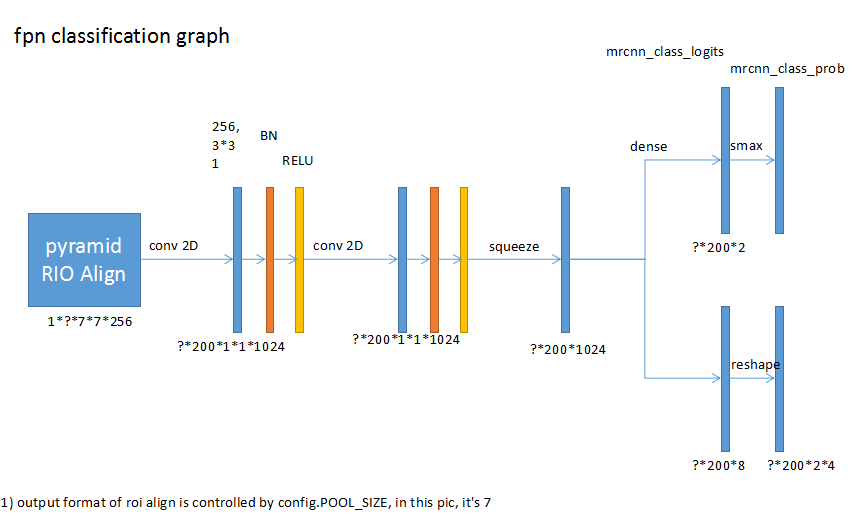
输出分类结果(上部)和bbox回归(下部)。每个类别有一个结果(不包括背景),上图中类别为2。
Mask生成网络
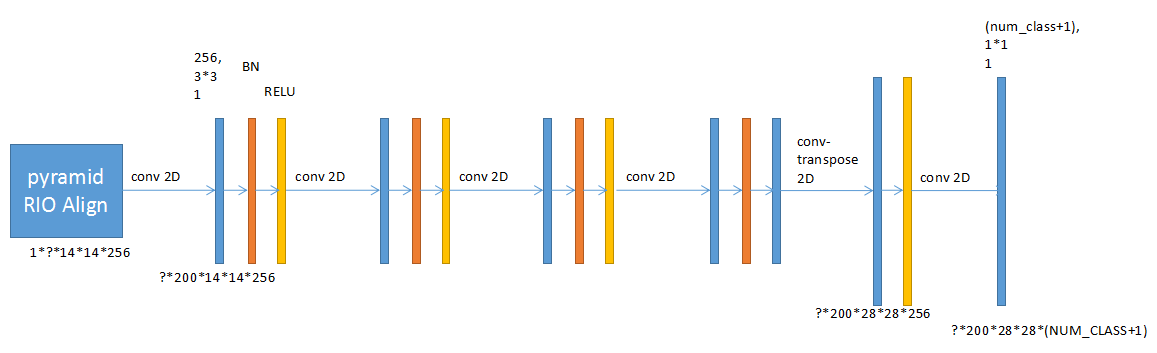 默认情况下生成28*28大小的Mask,每个类别一个Mask。推理时使用后处理将mask resize到bbox的大小,并填充0变成原图片大小(utils.unmold_mask)。
默认情况下生成28*28大小的Mask,每个类别一个Mask。推理时使用后处理将mask resize到bbox的大小,并填充0变成原图片大小(utils.unmold_mask)。
Gradient传递
PyramidROIAlign层阻止Gradient向ROI proposals传递,但是会向FPN传递。也就是说头部的反向传递部分对RPN网络不产生影响。代码参考models.PyramidROIAlign
其他模块
Detection target layer,Proposal layer, 以及推导过程中的Detetion layer都是普通的非学习的过程. Proposal layer选择6000个概率最大的anchor boxes,做一些后处理,使用NMS去重。得到的结果作为后续的输入。由于FPN的高精度层比较大,比如128128,会生成128128NUM_bbox_ratio个结果,以0.5,1,2三个box ratio来计算是128128*3=49152个,而且可能存在大量的重叠,如果不加处理输入到后续网络,会占用大量的内存。
Detection target layer把Proposal layer的输出进一步处理,生成合适的候选ROIs输入到后续网络,并为计算loss做准备。
Detection layer主要是根据目标分类和Bbox回归的结果,选择合适的ROI(去除背景,去除低概率的box,NMS去重)输入到mask生成网络。
ROIAlign 论文中这部分是使用插值的方式,将BBox对应的feature变换成7*7大小。matterport的实现直接使用了tf的resize。
Comments